本帖最后由 HomeByte 于 2020-11-3 19:38 编辑
C语言虽然是基础,但实际上是要求学者已经具备入门的能力,然后通过本章节将C语言里面几个比较重要的板块进行加深;如果学者对C语言并不了解,建议先通过网上搜索入门教程学习后再进入本章节。 1.数据类型1.1 类型定义
C语言标准中,常用的类型如下表格: 类型 | 存储大小 | 取值范围 | signed char | 1 字节(Byte),8bits | -128 到 127 | unsigned char | 1 字节,8bits | 0 到 255 | short | 2 字节,16bits | -32,768 到 32,767 | unsigned short | 2 字节,16bits | 0 到 65,535 | int | 2/4 字节,16/32bits | -32,768 到 32,767 或 -2,147,483,648 到 2,147,483,647 | unsigned int | 2/4 字节,16/32bits | 0 到 65,535 或 0 到 4,294,967,295 | long | 4 字节,32bits | -2,147,483,648 到 2,147,483,647 | unsigned long | 4 字节,32bits | 0 到 4,294,967,295 | float | 4 字节,32bits | 1.2E-38 到 3.4E+38 | double | 8 字节,64bits | 2.3E-308 到 1.7E+308 | bool | 忽略 | true/false |
然而在正常开发过程中,由于平台(主控芯片类型)不同,会导致我们使用的变量有位数的差异,比如表中的int在不同位(16位/32位)机的表现不同,因此我们需要一个抽象定义来解决这个跨平台问题: 实际使用类型 | 存储大小 | 打印符号 | int8_t | 1 字节(Byte),8bits | %d | uint8_t | 1 字节,8bits | %u或%c或%x(16进制小写,%X大写) | int16_t | 2 字节,16bits | %d | uint16_t | 2 字节,16bits | %u或%x | int32_t | 4 字节,32bits | 32位机器%ld,64位机器%d | uint32_t | 4 字节,32bits | 32位机器%lu,64位机器%u或%x | int64_t | 8 字节,64bits | 32位机器%lld,64位机器%ld | uint64_t | 8 字节,64bits | 32位机器%llu,64位机器%lu | float | 4 字节,32bits | %f | double | 8 字节,64bits | %lf | bool | 忽略 | %d或%s |
这个抽象定义在Linux标准头文件已经实现,我们只需要在开发时包含一下头文件即可:#include <stdint.h>, bool类型需要包含另外一个头文件:#include <stdbool.h> 1.2 类型格式化在上一章节中我们理解了类型占用的空间,还有输出格式,但还是存在一些困惑的地方,这里做一些解释,首先是格式输出(比如使用printf打印),我们必须要解决一个不同位数机器的兼容问题,在我们的Ubuntu Server中可以找到一个目录:~/workspace/basics/c/3_1_typedef,该目录里面的源码对应本章内容,如下:  
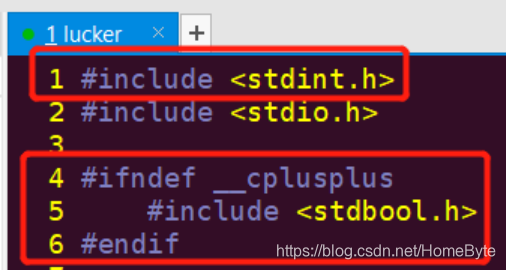
说明:定义__cplusplus说明是c++的编译器进行编译,c++原生支持bool类型,因此可以忽略该头文件,不然会有编译告警。 1.2.2 定义变量:
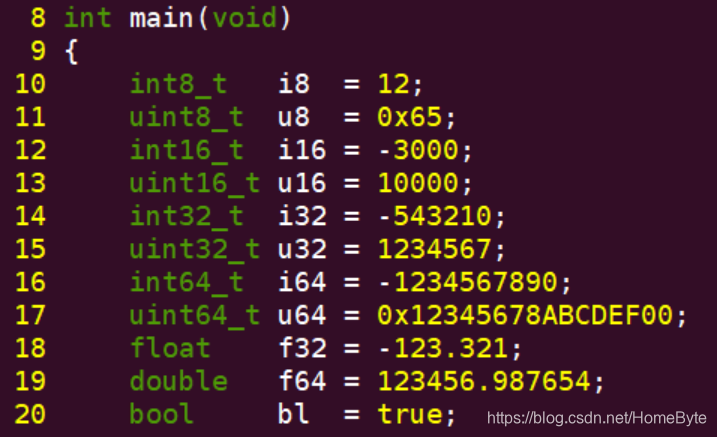
1.2.3 printf格式化输出:
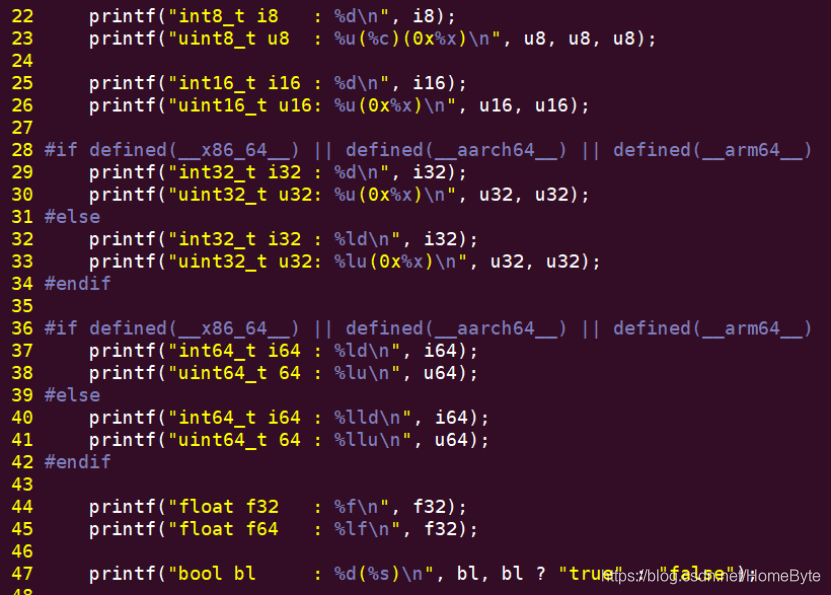
说明: #if defined(__x86_64__) || defined(__aarch64__) || defined(__arm64__) 这段宏定义是在区分代码是在64位机器上还是32位机器,不同位数的打印输出是不一样的,我们的Ubuntu Server是64位机器的;如果没有这段宏,代码会出莫名其妙的运行时问题,而且是令人百思不得其解的现象。 1.2.4 编译及运行:
注意,嵌入式的开发过程不要使用微软的工具(比如VS)来编译或者运行,不然你的代码会有一堆冗余的代码去将就WIN32和微软编译内核版本的问题,比如上述例子中的bool类型,如果使用旧的微软编译器(低于Visual Studio 2013的版本),一定会出现编译不通过的问题,而我们需要做一个修改来将就这个编译内核的问题: 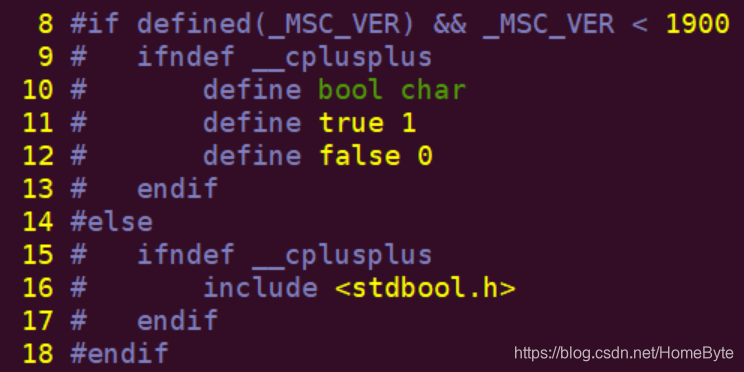 这种兼容在嵌入式开发是绝对的败笔,除非你的软件是开源软件,需要考虑各方的使用,如果是企业产品的开发,不建议使用微软的编译工具。 目前我们暂不考虑编译到开发板上运行,先通过gcc来编译测试: 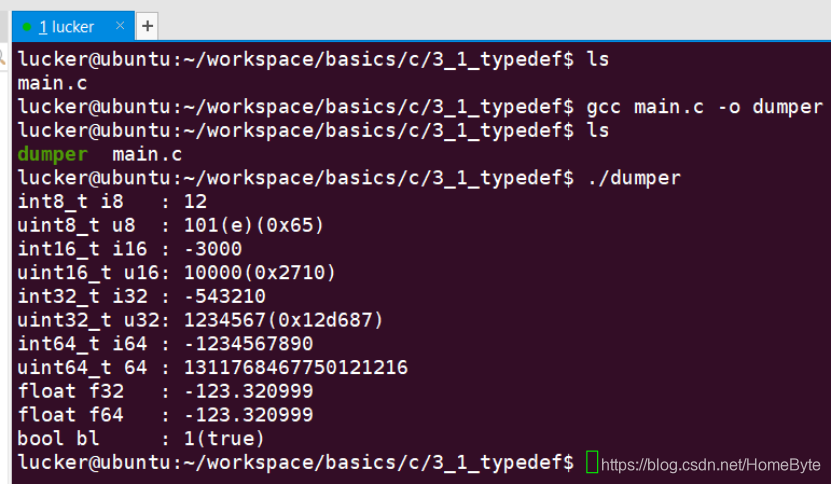 这段代码可以在任何基于Linux平台(包括安卓)中被无缝移植,而且编译无任何警告和错误,运行也不会出现奇怪的问题。 这种格式化也经常被用来通过sprintf把数值格式化为字符串,比如:  当一个C/C++原码文件被编译链(比如gcc/g++)编译及链接成为可执行程序后,由4个段组成,分别是:代码段,数据段,栈,堆。 代码段(.text)包含代码逻辑(函数),以及宏定义(#define)常量。 数据段包含3部分:.bss,.rodata,.data。 .bss: Block Started by Symbol,存放程序中未初始化的全局变量。 .rodata:read only data,用于存放不可变修改的常量数据。 .data:静态变量和已初始化的全局变量存储区。 栈(.stack)主要用来存放局部变量, 传递的参数, 存放函数的返回地址;程序运行过程中动态生成及回收,不需要用户回收存储空间。 堆(.heap)由malloc等API动态分配的内存区域,其生命周期由free决定;程序运行过程中动态生成,需要由使用者自行回收。 了解程序的组成存储区有利于开发过程中对程序的精简,比如我们可以选择变量内容及大小是直接编译进可执行程序(ROM)中,还是程序运行过程中才被实例化(RAM);如果代码量10W+行基本能很明显的出现差异,同样功能有的代码编译出来占用空间非常大,有的很精简,其中一个原因就是对底层存储分区的理解不同。 在我们Ubuntu Server目录:~/workspace/basics/c/3_2_variables,存放着本章节我们会用到的源代码文件;其中main_1.c的内容是针对变量/函数的分区存储结构做了描述: 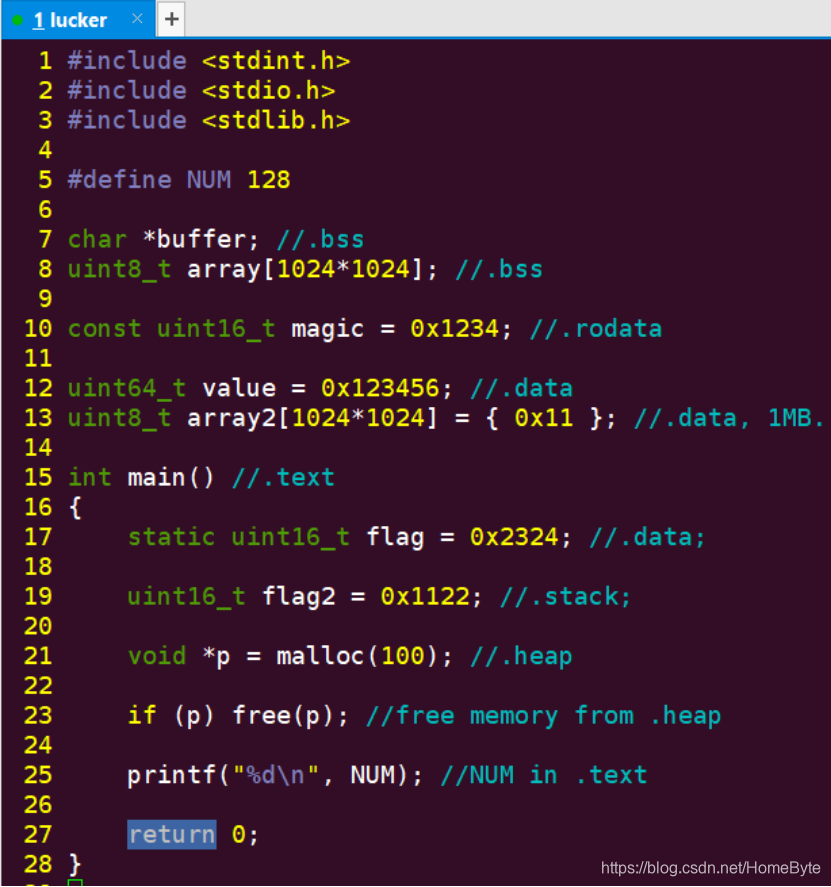 我们尝试保留及注释掉.data里面的一个存储空间,对比两者编译后程序的大小。  差别巨大: 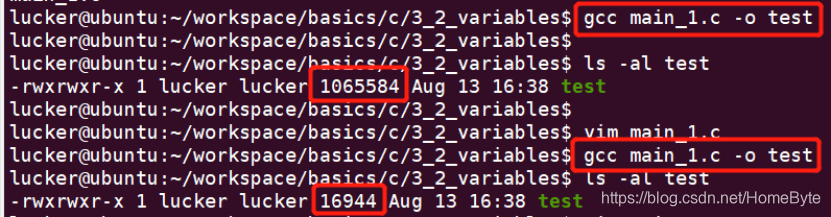 本节内容源码在点击:~/workspace/basics/c/3_2_variables/main_2.c中,主要讲解C语言中的动态类型变量定义的方法,需要使用到的关键字是:typeof(),该关键字是GNU C提供的一种特性,可以用来取得变量/函数的类型,或者表达式的类型。常用的方式如下: 
定义一个变量,可以是普通变量也可以是指针变量,然后typeof取得该变量类型并用于定义另外同类型的变量;比如图中所示的value。 b. 取得函数类型做函数指针。
主要用来取得函数的类型,并定义函数指针使用,图中所示的指针func就是取着函数add类型定义的。 c. 取得表达式类型做处理。
取得表达式相对较为复杂,图中所示,我们将函数add的运算结果导出来用于判断;该技巧同样可以用于函数调用失败后的多次重试。 编译运行如下: 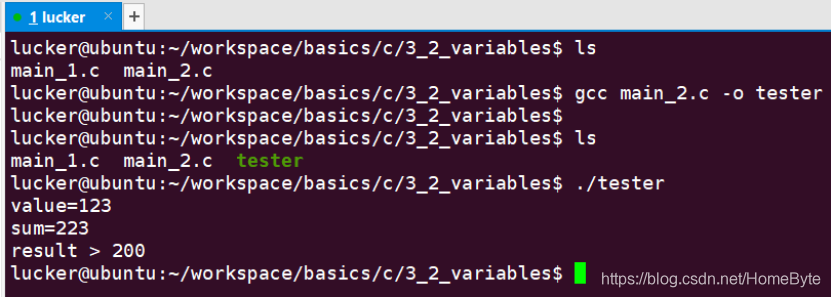 在C语言中,进行类型之间的转换有两种转换方式:隐式类型转换 和 强制类型转换。其中强制类型转换是由开发人员完成的,比如float val = (float)u8; 一般不会出现问题,所以我们重点关心隐式类型转换。 隐式类型转换是由编译器主动完成的,如果由低类型到高类型的隐式类型转换是安全的,不会发生截断;相反由高类型到低类型的隐式类型转换是不安全的,会发生截断产生不正确的结果:  四种情况下会发生隐式类型转换:赋值,算术运算,函数传参,函数返回值。 在源码文件:main_3.c中,我们列出了四种情况的例子: 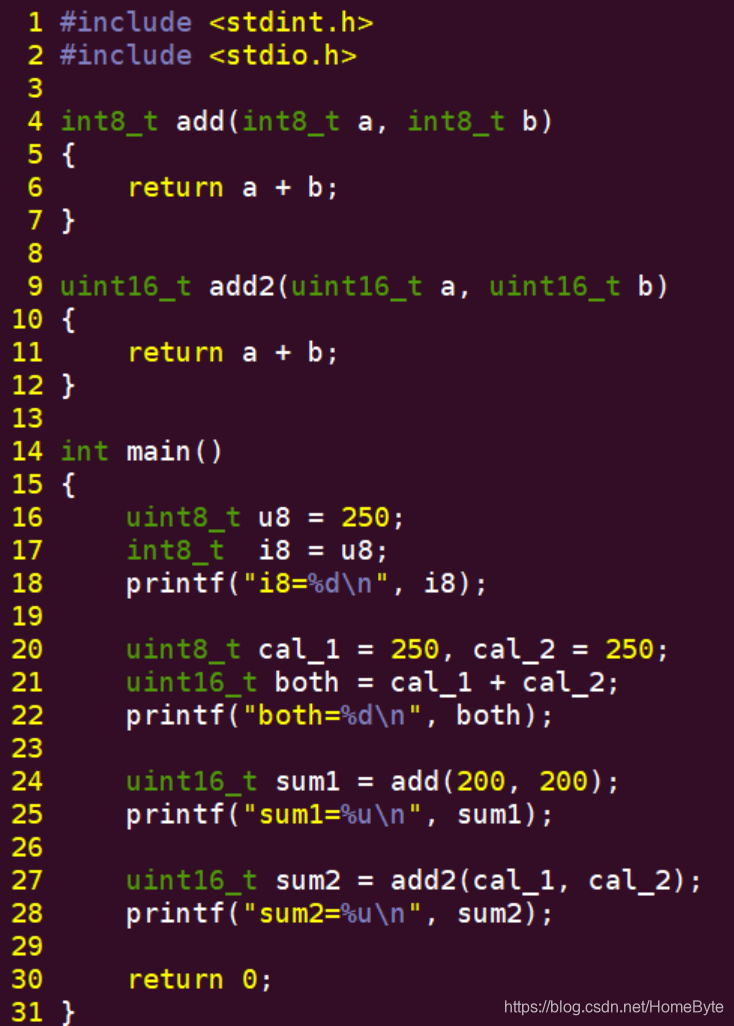
图中我们定义的类型uint8_t u8,并赋值为250;同时定义int8_t i8,然后把u8赋值给i8,显然这个过程出现类型不匹配的转换,由于250已经超过i8的最大范围,因此i8不在是数值250了。 b. 算术运算。
两个uint8_t类型相加,赋值给uint16_t,实际上编译器在执行该条指令时,会把两个uint8_t先转换为uint16_t,所以图中: uint16_t both = cal_1 + cal_2; 等价于: uint16_t both = (uint16_t)cal_1 + (uint16_t)cal_2; 隐式类型转换后数据正确。 c. 函数传参。
函数add的参数类型都是int8_t,而我们传入的200已经超过最大范围,因此传入的数据发生大类型到小类型的转换;同时函数返回值是int8_t,两个超过范围的int8_t相加得不到200+200=400的数值,如果相加也出现溢出,那么返回值更加不可测了。 d. 函数返回值。
函数add2的参数和返回值都是uint16_t,我们传入的两个uint8_t被转换为uint16_t,运算结果数值也是uint16_t,因此返回数值正确。 编译运行: 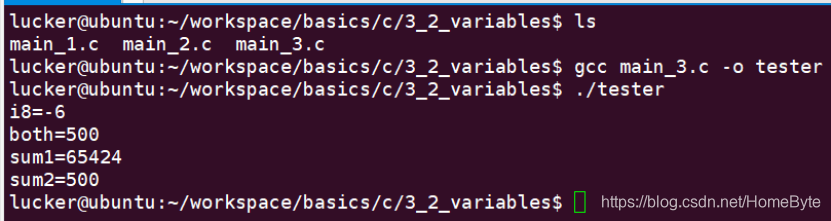 在编写程序的过程中,我们需要留意可能存在隐式类型转换的地方,避免由于数据类型转换导致的结果不可预测。
1.6 指针本章内容的源码在目录点击:~/workspace/basics/c/3_3_pointer 中。 1.6.1 指针与堆堆常见的操作函数有以下几个: void *malloc(size_t size) : 从堆中申请内存空间。 void *calloc(size_t nmemb, size_t size) : 从堆中申请内存空间并清零。 void *realloc(void *ptr, size_t size) : 调整已从堆中申请到的内存大小。 void free(void *ptr) : 释放从堆中申请到的内存空间。 以上的API需要包含头文件: #include <stdlib.h> void *memset(void *s, int c, size_t n) : 给内存空间格式化为指定值。 void bzero(void *s, size_t n) : 给内存空间清零。 以上的API需要包含头文件: #include <string.h> 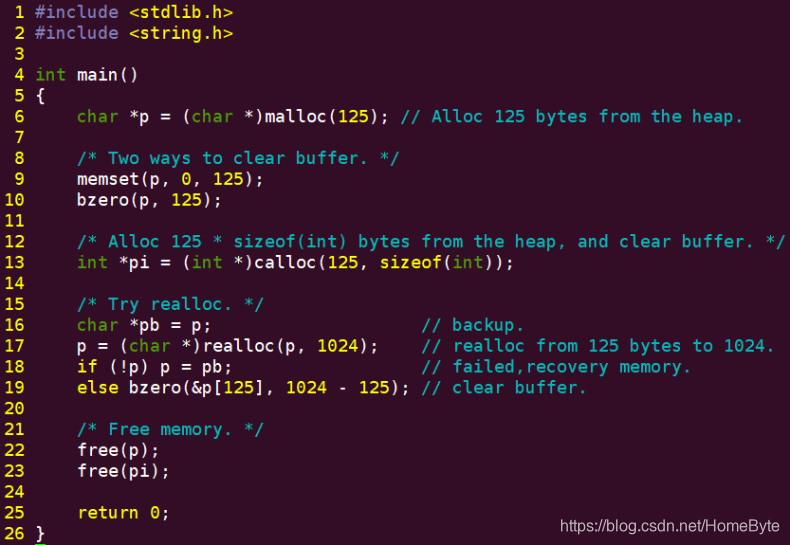
malloc返回值非NULL时表示成功,程序中没有做这个判断,出于严谨考虑大家在调用时最好做下判断;同时除非申请的空间极其巨大或者有内存泄漏,不然基本不会出现失败的情况。清零的方式有两种,可以使用memset,也可以使用bzero,建议使用bzero直观一点。 b. realloc。
该函数使用时需要注意,失败时会返回NULL,且先前分配的堆内存空间是不会被回收的,因此我们在调用该函数之前需要备份一下已申请的内存空间地址,这样申请失败的话还可以找回之前的数据;同时需要注意的是,重新申请成功后多出来的那部分内存空间有可能是没有被清零的,需要我们手动调用bzero进行清零。 c. 释放内存。
所有从堆中成功申请到内存空间,都需要通过free函数进行手动回收,不然会造成内存泄漏。 d. 内存拷贝。
从一片内存拷贝数据到另外一片内存可以使用函数:memcpy,比如: 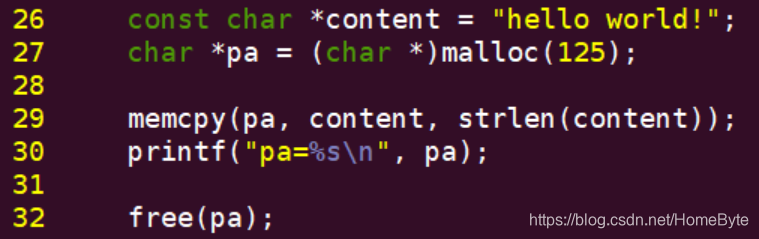 把content栈空间内容(hello world!)拷贝到堆中(pa)。
================================================================================================================================== 这样整个开发环境及交叉编译链就搭建好啦!!如果觉得对您有帮助并想进一步深入学习交流可以扫描以下微信二维码或加入QQ群:928840648
欢迎共同学习成长,有一群爱学习的小伙伴一起勉励!!加油!!也可点击

| 







 楼主
楼主