|
在实际项目中,我们常遇到类似于“因数据同步延迟超过5分钟导致报表滞后”等由于数据同步不及时而造成的窘境,为ETL工具性能瓶颈而苦恼。
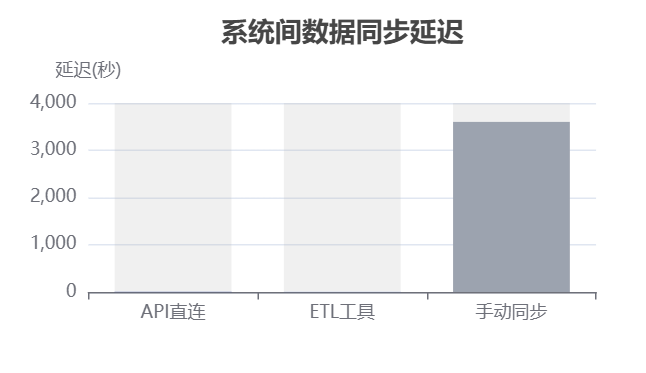
后来,在经过对不同ETL工具实测与调研后,我们总结出了市面主流十大ETL工具实战对比详解。为企业选择稳定、高效的ETL工具提供参考。
为什么选择合适的ETL工具对企业数据平台稳定性至关重要?
我们需要知道的是,选对ETL工具,可以减少系统集成失败、提升数据同步效率、保障数据血缘完整性。
而什么是“数据血缘”呢?
数据血缘指的是数据从源头到目标的完整轨迹,有助于审计、溯源和故障排查。可以举一个比较直观的类比,选择ETL工具就像选用一条精准的快递路线,既要速度,也要中转透明;一旦错选工具,就像包裹被频繁转运,不仅慢,还可能丢件。
在了解这些的前提下,我们才能更好地具有针对性地选择适合企业自身的ETL工具。
2025年十大ETL工具一览与关键性能对比
结论:不同工具在吞吐量、延迟、扩展能力方面差异明显,适合不同场景。_
RestCloud ETLCloud
首先,如果企业需要一款国产化、自主可控且功能全面的数据集成平台,RestCloud ETLCloud 是一个非常值得考虑的选项。它由谷云科技自主研发,代码自研率高达98.73%,完全符合信创环境要求,支持主流国产数据库与操作系统。ETLCloud 集离线批处理、实时同步(CDC/MQ)、文件与API数据集成于一体,采用可视化拖拽式流程设计,部署速度快,任务可自动分片并发执行,稳定支持百亿级数据同步,且内置完善的运维监控与告警机制。性能方面,根据实际测试,其同步效率比Kettle快24%、比DataX快近28%,非常适合对数据集成质量与安全性要求严格的企业级项目。
Talend Open Studio
Talend Open Studio则是另一款开源生态成熟的ETL工具,其吞吐量约为150GB/h,平均延迟在8秒左右。它的优势在于提供了直观的数据血缘可视化功能,同时通过插件可以实现异步处理,这让它在中型企业中备受欢迎,尤其适合那些对合规性和透明度有较高要求的组织。
Informatica PowerCenter
如果业务对性能和数据质量有极高的要求,比如金融或电信行业,Informatica PowerCenter是一个常见的首选。它能在高并发场景下实现每小时高达500GB的数据处理,延迟最低可达3秒。同时,它提供全面的异步架构支持以及强大的数据血缘追踪能力,是构建企业级数据集成平台的“豪华配置”。
AWS Glue
对于云优先战略的企业来说,AWS Glue是一个天然的选择。作为云原生ETL工具,它的吞吐量大约在400GB/h,平均延迟约4秒,并且可以与Amazon SQS无缝集成,实现异步处理。此外,AWS Glue依托AWS Data Catalog提供完善的元数据管理,非常适合构建现代化的数据湖或云端数据仓库。

Microsoft SSIS
在传统企业中,Microsoft SSIS依旧占有一席之地。它的吞吐量大约是250GB/h,延迟约6秒,虽然本身异步能力有限,但通过插件可以实现一定程度的异步处理。SSIS的数据血缘信息主要集中在Meta Data Store中,对于那些深度使用微软生态的企业来说,依然是一个性价比不错的方案。
Matillion
Matillion则针对云数据仓库场景进行了深度优化。它在Snowflake、Redshift等云环境中表现尤其出色,吞吐量约为350GB/h,延迟5秒左右,异步支持完善,且具备较强的数据血缘可视化能力。对于需要大规模云端数据集成的企业而言,这是一款“为云而生”的ETL工具。
Pentaho Data Integration
在预算有限、但拥有一定开发能力的企业中,Pentaho Data Integration是一个常被提及的选择。它的社区活跃,吞吐量约200GB/h,延迟在7秒左右,功能扩展更多依赖社区插件。虽然血缘追踪能力偏基础,但胜在灵活和低成本,非常适合中小型企业或技术驱动的组织。
Stitch
如果企业追求部署的简便性和轻量级集成,Stitch是一个不错的解决方案。它的吞吐量约220GB/h,延迟5秒,异步能力表现良好,不过在数据血缘方面支持有限。它特别适合数据量不大、团队希望快速上手并简化运维的场景。
Apache Hop
对于喜欢尝试新兴开源技术、且具备一定开发实力的团队,Apache Hop是一个值得关注的后起之秀。它的吞吐量大约在180GB/h,延迟6秒,采用模块化设计,灵活性强,同时具备开源的血缘追踪功能,特别适合那些倾向于二次开发的企业。
Fivetran
最后,Fivetran则以自动化见长,尤其适合追求“零维护”体验的企业。它的吞吐量约320GB/h,延迟4秒,异步处理能力完善,但在血缘追踪方面支持相对有限。它最大的优势是可以免除大量配置和维护工作,并且原生适配多种云数据仓库,非常适合以效率优先的现代数据团队。
企业如何根据业务需求选择合适的ETL工具?
先说结论,明确业务场景是选择的前提,按同步延迟、扩展能力、成本等维度匹配工具。
如何解决同步延迟问题?
步骤 1:测算目标同步延迟阈值(如 5 秒内);
步骤 2:选取平均延迟小于阈值的工具,如 Infrmatica PwerCenter(3 秒)、AWS Glue(4 秒);
步骤 3:做小范围PC,监控实际延迟,确保满足SLA。
如何处理高吞吐量场景?
建议选择具备较高并发能力的工具,如 Infrmatica(500 GB/h)或 AWS Glue(400 GB/h),并结合异步消息队列优化;
在实时数据流场景,可用 NiFi 或 Matillin 构建分布式流水线。
如何兼顾成本与运维?
云原生ETL工具(如 AWS Glue)采用按量计费,初期投入小;
本地部署工具(如 SSIS、Talend)长期稳定成本可控,适合数据量固定场景。
|









