TMS320C6701DSP线性调频信号数字脉冲压缩
线性调频信号具有抛物线式的非线性相位谱,能够获得较大的时宽带宽积;与其它脉压信号相比,很容易用数字技术产生,且技术上比较成熟;所用的匹配滤波器对回波信号的多卜勒频移不敏感,因而可以用一个匹配滤波器处理具有不同多卜勒频移的回波信号。这将大大简化信号处理系统,因此它在工程中得到了广泛的应用。采用这种信号的雷达可以同时获得远的作用距离和高的距离分辨率。数字化的脉冲压缩系统具有性能稳定、受干扰小、工作方式灵活多样等优点,是现代脉压系统的发展趋势。
本文以TI公司的高性能的TMS320C6701浮点DSP芯片作为实现数字脉冲压缩的核心器件,实现了线性调频信号的频域数字脉冲压缩。
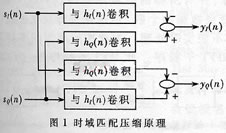
1 数字脉冲压缩原理
数字脉冲压缩采用数字信号处理技术完成相关匹配滤波,通常采用时域处理和频域处理两种方法实现这一过程。
1.1 时域脉冲压缩处理
时域脉冲压缩直接对雷达回波信号进行卷积运算,如图1所示。其算式如下:
s(n)=s1(n)+jsQ(n);h(n)=hI(n)+jhQ(n)
y(n)=s(n)×h(n) (1)
式中,s(n)为A/D采样之后的回波信号;h(n)为匹配滤波器的冲激响应信号;y(n)为时域脉压输入信号。采用时域方法进行脉冲压缩且当卷积运算速度达到A/D采样速度时,可以进行实时脉冲压缩处理,输入信号的长度不受滤波器阶数的限制。但当A/D采样频率较高时,脉压处理将无法实时完成。
1.2 频域脉冲压缩处理
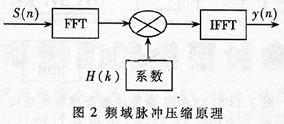
频域脉冲压缩先对输入回波序列进行FFT变换,将离散输入时间序列变换成离散谱,然后乘以匹配滤波器冲击响应的离散谱,再用逆FFT还原成压缩后的时间离散信号,如图2所示。其算式如下:
S(k)=FFT(s(n));H(k)=FFT(h(n))
y(n)=IFFT(S(k)×H(k))=IFFT(FFT(s(n))×FFT(h(n))) (2)
在大时宽信号时,采用高速FFT算法,大大减少了运算量,提高了运算速度,因而现代雷达体制广泛采用的是频域算法。频域算法的实现要求发展快速傅立叶变换的硬件,以前多用高速FFT运算器件实现频域脉压。但随着通用DSP器件速度的不断加快,这些专用FFT器件不仅没有了高速FFT算法运算上的优势,同时还伴随有功能单一、不便于功能扩展、成本高、实现电路复杂等劣热,因此逐渐被淘汰,取而代之的是高速DSP器件。本文正是TI公司的高性能的TMS320C6701浮点DSP来实现频域数字脉冲压缩。
2 TMS320C6701的结构和性能
TMS320C6701(以下简称C6701)是TI公司近年来推出的含多个处理单元的一种新型新点DSP芯片。它采用VLIW结构,在167MHz的主频下可以得到1GFLOPS的高处理速度。CPU中包括报两套对套的运算单元(L,S,M,D)和相应的两套寄存器组,每组有16个32位宽的寄存器。每个功能单元输入输出端口相互独立,可实现并行处理。
C6701的地址总线为32位,寻址范围达到4GB。存储空间可分为四部分:片内程序空间、片内数据空间、外部存储空间和内部外围设备空间,可通过对五个BOOTMODE引脚的灵活设置设定各空间的地址范围。片内数据空间又分成两块,每一块RAM被组织为八个2K×16的存储体,使得CPU可以同时访问不同存储体的数据,而不会发生冲突。片内程序空间可设为Cache,存储经常使用的代码,减少片外访问次数,从而提高程序运行速度。
C6701的外围端口包括DMA控制器、主机接口(HPI)、中断选择等。两个多通道缓存串行口(McBSP)除多通道、比缓存外,还支持多种数据格式、硬件A/μ率压扩展 、位时钟和帧时钟的灵活编程,另外还提供SBSRAM、SDRAM等高速存储器的无缝接口。
C6701采用间接寻址,有线性方式和循环方式 两种。程序按三级流水线执行,即取指、译码、执行。C6701具有丰富 的指令集,内含50余条指令,且大部分是单周期的,可完成数据传输、算术逻辑运算和程序控制等功能。
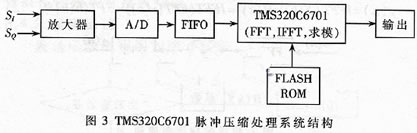
3 频域脉冲压缩系统的硬件结构和原理
以C6701为核心器件,辅以相应的输入输出电路,可完成数字频域脉冲压缩系统的设计。实现的硬件结构如图3所示。
将正交的两路采样信号输入到放大器。放大器一方面对信号放大。另一方面也将放大的信号以差分方式输出。信号以差分方式输出是为了抑制掉高阶谐波分量,滤掉各种干扰信号(如电源和地的噪声),这样有利于提高A/D转换器的性能。系统选用了12位A/D转换芯片AD9220,该芯片具有单端输入和差分输入两种方式,因此,放大器输出信号能直接输入到AD9220进行模/数转换。两路回波信号经AD9220正交采样后,再经符号扩展成16位存入FIFO。C6701处理器将输入的32位信号送到内部RAM,按照图2所示的方法进行频域脉压处理。首先对输入信号进行FFT变换,将信号变换离散的频域抽样值。然后将FFT变换 结果和匹配滤波系数相乘。设计中将匹配滤波器的系数存放在FLASH ROM中,上电后将此系数搬移到内部高速数据RAM,然后才进行运算。为了获得-40dB以下的副瓣电平,通常将匹配滤波器的系数进行汉明加权后存放在ROM中。再后,对相乘结果进行反傅立叶变换,完成频域脉压。量后,将反傅立叶变换结果进行求模运算,得出离散的脉压信号并将其输出。由于C6701是浮点处理器,既保证了较高的精度,又不用考虑溢出问题,使得有限字长的影响可以忽略不计。当雷达发射周期较长时,可以将输入信号分段进行处理,每段单独进行频域脉冲压缩,然后按照重叠保留法将每段压缩结果组合成整个信号脉压输出。
以上脉压算法可以通过编程在DSP内部实现,这不仅简化了电路、减小了体积、提高了系统的可靠性,而且扩展了系统的功能,使系统具有较高的灵活性,即在不改变硬件电路的情况下,只需改变系统软件和外部ROM中的匹配系数,就能完成不同信号的脉冲压缩功能。

4 频域脉冲压缩系统的软件设计
频域脉冲压缩系统的软件设计主要采用TI公司的CCS软件开发。在CCS下,软件可分为三个阶段。第一阶段,根据任务编写c语言程序,并对程序进行优化。当代码性能较低时,为改进代码性能进入第二阶段,第二阶段利用优化方法重新编写C代码,并检查所生成的代码性能。第三阶段,从C语言程序中抽出对性能影响很大的程序段,使用线性汇编语言重新编写,然后使用汇编优化器对线性汇编程序进行优化,从而得到满意的代码性能。根据以上方法,编写出的脉冲压缩系统的软件包括系统初始化子程序、DMA子程序、正傅立叶变换FFT子系统和反傅立叶变换IFFT子程序、复数相乘子程序、求模子程序等。其流程如图4所示。
在执行系统初始化程序时,要对系统的控制状态寄存器、外部存储器接口控制寄存器等进行参数设置,保证系统按要求正常工作。为提高系统效率,系统通过DMA通道从外部CE2空间将数据读入片内RAM,所以初始化程序必须设置好外部存储器CE2空间的控制寄存器。在进行FFT变换子程序的设计时,因为基四算法比基二算法快,并且频率抽取算法比时间抽取算法能更好地发挥C6701的并行运算能力,所以采有基四频率抽取算法。对4096点信号进行FFT变换,所需时间≤400μs。编写的复数数组相乘通用子程序实现4096点运算所需时间≤95μs。对于反变换,可以直接得用前面的FFT算法实现,即先对输入频域序列作共轭变换,然后进行FFT运算,并对所得的时域序列再作共轭变换 ,最后除以FFT变换 数据的个数。但这样进行反变换所需要的时间较长,不能实时处理。为此按照其四频率抽取的算法编写了IFFT子程序,此IFFT子程序经过CCS优化之后,对4096点逆变换来讲,需要400μs左右。本程序和FFT子程序配合使用,可以方便地实现信号的正傅立叶变换和傅立叶变换,而不需要进行位反转操作,不仅节省了存储空间,而且加快了运算速度。为求复信号的模值,可以采用迭代等算法编写求模子程序。
系统初始化程序如下:
system_intr()
{LOAD_REG_FIELD(csr,0,0,2);
SET_REG(ICR,0xFFF0);
REG_WRITE(EXITERNAL_INTR_POL_ADDR,0);
INTR_MAP_RESET();
SET_REG(ISTP,0);
LOAD_FIELD(EMIF_CE2_CTRL_ADDR,5,READ_SETUP,READ_SETUP_SZ);
LOAD_FIELD(EMIF_CE2_CTRL_ADDR,8,READ_STROBE,READ_STROBE_SZ);
}
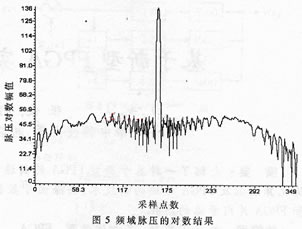
图5是利用CCS提供的数据图形显示工具进行坐标变换后的脉压结果。此线性调频脉冲参数为:时宽32μs,带宽5MHz,采样频率为5MHz。
采用先进的高速数字信号处理器,使得大点数脉冲压缩能够在很短的时间内高质量地完成。同时利用本系统,只要改变存储器的系数,就可以方便地实现非线性调频脉冲压缩及其它滤波,具有通用性。对于要求更高速度的系统,可采用多片TMS320C6701并行处理。而TMS320C6701所带的符合IEEE1149.1标准的JTAG口能够方便地进行了多片级联调试,再加上开发软件CCS所具有强大的功能,可以大大提高工作效率和缩短产品的开发时间。
|
|








 楼主
楼主
